Analysis of Excerpts For Sentence Classifier
This post will discuss the options for using the given datasets to train a sentence classifier. Next, this post will also analyze how many sentences are in each excerpt, and transform the labelled excerpts into a dataset of labelled sentences.
Sentence Classifier Objectives
After the last meeting with the researchers, it was discussed that it would be preferable to have a classifier that can identify sentences within a document that are discussing accountability. The simplest approach to take for this would be to have a classifier that can operate sentence by sentence and output the classification of accountability or not. Note the alternative would be to identify spans within a document, but given the dataset as is, this seems like a less likely approach to achieve a good performance. So, the first approach that will be tried, is to train a sentence based classifier from the given excerpts.
There is some preliminary analysis of the given dataset, analysis the words present and the class labels, see the previous posts:
However, the length of the excerpts of the datasets has not yet been analyzed. In the following sections of this post, first an analysis of the existing excerpts will be shown, and then the implications with regards to classifying as a sentence classifier will be discussed. The jupyter notebook that was used to produce the following results is also posted online in the github.
Analysis of Excerpt Lengths
Overall Excerpt Length Distribution
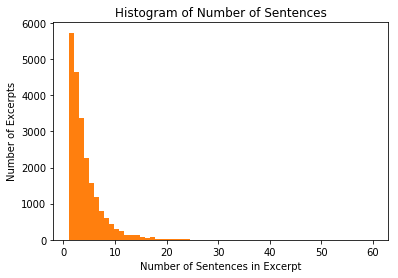
The overall distribution of number of sentences for each excerpt is shown in the histogram below. The majority of excerpts have a length of less than three sentences, and the most frequently occurring length is 1 sentence. This is good news, since there seems be already a sufficient amount of training data as excerpts that are a single sentence. Note the longest excerpt is quite long, consisting of 60 sentences.
Excerpt Length Distribution by File
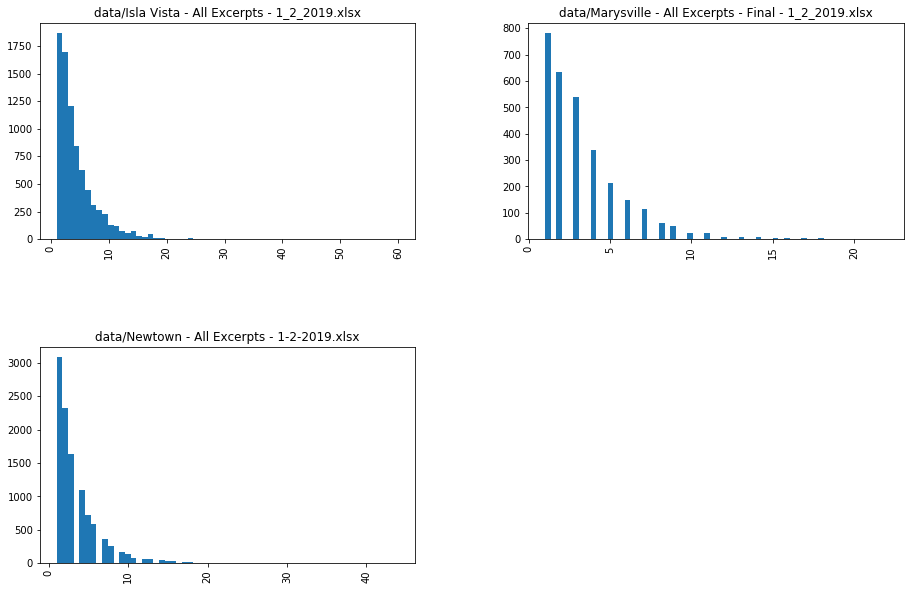
The analysis can be repeated on each file individually, to make sure that none of the files have particularly long excerpts, that would make it more difficult to train a classifier on all three files. Looking at these histograms, a similar pattern appears for all datasets, indicating that they all have a reasonably large proportion of single sentence excerpts and excerpts with less than 5 sentences.
Summary Analysis by Article
The following table shows summary statistics of the excerpt lengths for each file, including the percentiles below a certain number of sentences. For example, this shows that for all three articles, 50% of the articles are less than three sentences in length, and 75% of articles are less than 5 sentences in length. The mean is also shown, but this mean would be not a good representative statistic because the distribution is very skewed. The min and max number of sentence in each excerpt is also shown for each file.
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| file | ||||||||
| data/Isla Vista - All Excerpts - 1_2_2019.xlsx | 8127.0 | 4.106189 | 3.876340 | 1.0 | 2.0 | 3.0 | 5.0 | 60.0 |
| data/Marysville - All Excerpts - Final - 1_2_2019.xlsx | 2978.0 | 3.345198 | 2.666752 | 1.0 | 1.0 | 3.0 | 4.0 | 22.0 |
| data/Newtown - All Excerpts - 1-2-2019.xlsx | 10767.0 | 3.480821 | 3.190377 | 1.0 | 1.0 | 2.0 | 4.0 | 44.0 |
Based on these results, it seems there is a significant number of existing excerpts of a length of a single sentence, so these excerpts will be further analyzed, as a possible prospect for training the sentence classifier. The biggest issues present in the data, is that several excerpts are quite long, with many over 20 sentences, these excerpts will cause issues in both training and testing a sentence classifier due to their excessive length. These extra long excerpts will also be analyzed in the upcoming sections.
Analysis of Single Sentence Excerpts
First we can assess the number of single sentence excerpts in each file, and with each account label. The results are shown in the output below.
0 5284
1 446
Name: ACCOUNT, dtype: int64
data/Newtown - All Excerpts - 1-2-2019.xlsx 3085
data/Isla Vista - All Excerpts - 1_2_2019.xlsx 1864
data/Marysville - All Excerpts - Final - 1_2_2019.xlsx 781
Name: file, dtype: int64
This shows that there is a good number from each event dataset. The main issue that could arise however is that there are only 446 single sentence excerpts labelled with accountability. This is quite a low number if it is to be used for both testing and training.
Analysis of Long Excerpts
There are several exceedingly long excerpts of over 25 sentences. This may be due to errors in the sentence tokenization, and so will be inspected. First we can assess the breakdown of label and files with long excerpts. Shown below is that for super long excerpts, there are very few with the label accountability, only 5.
0 32
1 5
Name: ACCOUNT, dtype: int64
data/Isla Vista - All Excerpts - 1_2_2019.xlsx 19
data/Newtown - All Excerpts - 1-2-2019.xlsx 18
Name: file, dtype: int64
Descriptive statistics providing more details are shown in the following chart.
| excerpt_lengths | ||||||||
|---|---|---|---|---|---|---|---|---|
| count | mean | std | min | 25% | 50% | 75% | max | |
| ACCOUNT | ||||||||
| 0 | 32.0 | 32.09375 | 6.060764 | 26.0 | 28.0 | 30.5 | 35.0 | 48.0 |
| 1 | 5.0 | 38.80000 | 14.549914 | 27.0 | 29.0 | 30.0 | 48.0 | 60.0 |
Below is one example of an extra long excerpt with the label accountability (only one is shown because they are quite long). It can be seen that there are many sentences in this long excerpt that would not be clearly related to accountability. So these long excerpts will be contributing much noise into the training and testing of a sentence based classifier.
********************************************
Some of Elliot Rodger's online posts leading up to Friday's shooting:
One year ago: Rodger begins revealing his views on women, dating and his own life in comments on several YouTube videos. One video
shows students partying in Isla Vista, Calif., during Deltopia, a notorious all-day party in Isla Vista. "It angers me so much to see these
people having so much fun here. I've lived here for over a year now, and it's been such a miserable experience. I haven't been invited to a
single party, and all the girls ignore me when I walk around at night."
Dec. 2, 2013: Rodger posts a photo to Facebook and Google Plus, sitting with sunglasses inside a black BMW with a license plate that
eventually would match the car involved in the shooting.
Jan. 1, 2014: Rodger begins considering his plot, according to a 141-page manifesto, setting April 26 to carry out his plan.
Feb. 10: Rodger uploads the first of at least 22 videos to YouTube, titled "Enjoying the sunset in Santa Barbara." Rodger doesn't speak
during the nearly two-minute video filmed from a car.
April 20: Rodger tweets a link to a video later taken down from his YouTube channel titled "Why do girls hate me so much?" A video with
the same title is re-uploaded Friday, May 23, the day of the killings. "I don't know why you girls are so repulsed by me. It doesn't make
sense," he said. "I do everything I can to appear attractive to you. I dress nice, I'm sophisticated. I'm magnificent. I have a nice car, a
BMW. Well, it's nicer than 90 percent of the people in my college."
April 24: Rodger wakes up with a cold and decides to postpone his plan to May 24. April 30: Authorities do a well-being check on Rodger after his family calls police about his YouTube videos. Rodger says in his manifesto
that he tactfully tells them the videos were a misunderstanding. "If they had demanded to search my room ... that would have ended
everything. For a few horrible seconds, I thought it was all over."
May 20: Rodger posts a 59-second video that shows his face as he drives around wearing sunglasses and a collared shirt, playing
George Michael's 1988 hit "Father Figure." Rodger does not speak, but the description of the video says: "I'm awesome. Yeah, you better
believe it. (Expletive) you haters."
May 23: Rodger posts several more videos to YouTube, including his detailed plan titled "Elliot Rodger's Retribution." "All you popular
kids, you've never accepted me; now you'll all pay for it," he said.
********************************************
It seems like these passages are way to long to be of use in training for sentence classification. Breaking passages this long up into sentences to use for training would add a lot of noise to the training data, and this would be better to avoid. Given the data set is quite large, with thousands of existing excerpts, removing these will not hurt the training, and given that these particular excerpts would be contributing quite a lot of noise, it would be best to remove them.
Given this insight, the charts were inspected again, to consider removing even more excerpts that are too long. Since 75% of the data has excerpts of less than 5 sentences, if there is enough accountability labels present in this 75% subset of the dataset, it might be best to restrict the new dataset for training sentence classifiers to only use the excerpts with less than 5 sentences.
Compare Class and File Balance in Short Excerpts Only
A break down of the excerpts containing five sentences or less is shown below. The counts of the labels is shown (1 = accountability, 0= not accountability), and the number of excerpts in each file is also shown. It looks like a reasonable ratio of account to not account labels, given that there is a class imbalance in the overall dataset as well.
0 3468
1 803
Name: ACCOUNT, dtype: int64
data/Newtown - All Excerpts - 1-2-2019.xlsx 1908
data/Isla Vista - All Excerpts - 1_2_2019.xlsx 1891
data/Marysville - All Excerpts - Final - 1_2_2019.xlsx 472
Name: file, dtype: int64
A detailed breakdown of the sentence counts for each file for each account label with excerpts of length 1-4 sentences is shown below.
| Number of Excerpts | |||
|---|---|---|---|
| file | Accountability label | Number of Sentences in Excerpt | |
| data/Isla Vista - All Excerpts - 1_2_2019.xlsx | 0 | 1 | 1638 |
| 2 | 2740 | ||
| 3 | 2655 | ||
| 4 | 2524 | ||
| 1 | 1 | 226 | |
| 2 | 646 | ||
| 3 | 969 | ||
| 4 | 840 | ||
| data/Marysville - All Excerpts - Final - 1_2_2019.xlsx | 0 | 1 | 743 |
| 2 | 1170 | ||
| 3 | 1386 | ||
| 4 | 1172 | ||
| 1 | 1 | 38 | |
| 2 | 102 | ||
| 3 | 231 | ||
| 4 | 176 | ||
| data/Newtown - All Excerpts - 1-2-2019.xlsx | 0 | 1 | 2903 |
| 2 | 4260 | ||
| 3 | 4473 | ||
| 4 | 3976 | ||
| 1 | 1 | 182 | |
| 2 | 382 | ||
| 3 | 438 | ||
| 4 | 404 |
A new dataframe containing only sentences from excerpts of length less than 5 will be created and saved to csv for future use. A summary of the previous table showing the counts for just each account label and file is shown in the following table. The far right column also shows the number of total sentences with each file and each label. This would give an idea of the class balance if it would be desired to used only individual sentences to test and train the classifier.
| file | Accountability label | Number of Excerpts with < 5 sentences | Total Number of Sentences |
|---|---|---|---|
| Isla Vista | 0 | 9557 | 24695 |
| 1 | 2681 | 8676 | |
| Marysville | 0 | 4471 | 8389 |
| 1 | 547 | 1573 | |
| Newtown | 0 | 15612 | 34400 |
| 1 | 1406 | 3078 |
The conclusions that can be drawn from this is that, it seems like removing the long excerpts will not have a big affect on the balance of classes or the balance of articles from the original dataset. This is good news, to be able to have a classifier trained more directly on shorter passages, which will be closer to its intended purpose. This only risk involved is that the distribution of features is not preserved. Comparing the balance once transformed into a dataset of individually labelled sentences (the far right column), this shows that in this case also the balance will not be affected greatly.
Assessment of Using this Data for a Sentence Classifier
One issue to consider, is that in using this transformation, additional noise is possible being introduced into the labels. For example, in an excerpt of four labels, it is possible that only one out of the four sentences actually makes a statement about accountability, that means there are three new sentences added to the training set that are incorrectly labelled. Incorrectly labelled training data is a problem known as “label noise”. To assess the overall possible amount of noise being introduced by this approach, lets assume each excerpt actually only contained one sentence about accountability. In this case, we can calculate how many sentences we now have in the short excerpts and full excerpts dataframes that are inccorrectly labelled.
Percent incorrect sentences out of short excerpts sentences dataset: 65.15789473684211
Percent incorrect sentences out of full excerpts sentences dataset: 86.92854690794958
This is a fairly significant amount of noise being introduced into the labels. The specific type of label noise being introduced in this case is asymmetric binary, random label noise, known as NAR label noise (noisy at random). The assumption made is that the noise introduced is independant of the features of the data, but not independant of the true class label.
Only false positive labels are being introduced, since all the sentences in an excerpt labelled as accountability are now being given the label accountability. It is a lot less likely there are many sentences in the excerpts that were labelled as not accountability, that should actually be labelled as accountability, resulting in the asymmetric introduction of label noise being introduced. These considerations are important, since with correct assumptions about label noise introduced, label noise filters can be used.
Label noise in the test set could also be an issue, but luckily we have a dataset of single sentences of sufficient size, that this could be used to make up the test data.
Approaches to Use Excerpts to Train Sentence Classifier
There are two factors to consider in converting the existing labelled excerpts into labelled sentences.
- How to train the classifier
- How to test the classifier
How to Test
The ultimate objective in the end would be to use the classifier on an article sentence by sentence and identify which sentences are talking about accountability. To evaluate the performance of operating in this manner, the testing data used would have have to be passed in as single sentences. Therefore, it would be important to use a test set of only single sentences. The two approaches for this are:
- only evaluate with the excerpts that already exist as single sentences
- use the excerpts converted to labelled sentences
There are some issues with both of these approaches.
Evaluate on only single sentence excerpts
The main issue with this, is that the distribution of features may different in the single sentence excerpts than the rest of the data set. For example, the fact that these single sentences were able to fully capture a statement about accountability, indicate that perhaps they have some unique sentence structure and terms that would not be present throughout the rest of the training data of excerpts that were more than one sentence. There are many issues that can arise from having a test set with a different distribution of features from the training set.
If the data is trained as well only on single sentences, then this would likely lead to the best possible performance in this situation, since it is learning the features relevant to single sentences and evaluating based on sentences with those features as well. The main issue with this approach is that this greatly restricts the size of the dataset, and likely misses out on many examples of discussing accountability that is not present in these few excerpts. However the size of this data of single sentences alone, would actually be sufficient to train a simple classifier.
Evaluate on sentences from multi-sentence excerpts
Another approach that would increase the size of the usable data, and also likely make the classifier able to generalize to more ways of discussing accountability, would be to evaluate based on the excerpts that were transformed into single labelled sentences.
The main issue with this approach, is that it is possible this would be introducing too much label noise into the evaluation. The amount of label noise, could be as much as 65% of the labels from the short excerpts dataset, in which case the evaluation of results would have a high variance. The fact that the label noise introduced by this method is asymetric will also pose additional issues with the evaluation.
How to Train
The next issue to consider is how to train. This method is more straightforward to deal with, since it can be determined by experimentation, and the evaluation of the results with each approach can be used to determine which training method was most appropriate.
Using Only Single Sentence Excerpts
The issue with this method as mentioned before, is that the excerpts with only single sentences may contain unique features, and have a very different distribution of features from the rest of the dataset. Also the size of data available for training is reduced, however certain model will still be ok with this size of data.
Converting Excerpts into Labelled Sentences
The next approach, to convert more of the dataset into labelled sentences will increase the size of the data, but result in training in the presence of label noise. Asymmetric label noise can be tricky to deal with in training, however there are existing approaches such as noise filters and noise robust models that can be used to accommodate this.
Using Original Length Excerpts
Using the original full excerpts for training would reduce the amount of label noise, but once again it would have the issue of making the features and representation of the training set differ from the test set, which will likely hurt the performance. Instead of dealing with the noise in the labels, the noise will exist in the feature space, and dilute the representations to become less meaningful. A classifier trained on this may have issues applied to documents that have a significant difference in length and representation of features.
Proposed Approach
Based on this analysis the proposed approach to assess the options is as follows:
1) Evaluation with single sentence excerpts: use clear cut evaluation with minimal noise to evaluate training approaches
- train with singles sentences
- train with full excerpts
- train with excerpts converted to labelled sentences
2) Evaluation with excerpts converted to labelled single sentences: compare the same training methods as previous, this comparison will indicate the effectiveness of evaluating with the larger dataset.
3) Evaluate on full excerpts: this is the method that was used previously, and can be used to compare to the new sentence based approach to determine if there is a drop in performance.
The simplest, quickest and most trustworthy method is to use only the dataset of single sentences for both training and evaluation. This method should be used for testing and experimentation with models, and then the proposed approach for extending the included dataset will be tested on only the higher performing classification methods based on the results from single sentences.