Policy Label Analysis
This post will analyze the policy label. This label is of particular interest to the researchers, so the sub-types of this label will be analyzed.
The sub-types of the policy label are: [‘OtherAdv’, ‘VictimAdv’, ‘Guns’,’InfoSharing’, ‘MentalHealth’, ‘Other’, ‘Practice’, ‘Immigration’]
These labels will be analyzed in the following ways:
- Text Visualizations: visualizations will give an idea of the content of each topic based on the words in the texts of the excerpts, as well as how similar are these subtopics, with a 2d representation visualization using dimension reduction
- Label Counts and Label Co-Occurrences: Graphs will show the break down of the number of labels of each type used in the test and the train, and the number of excerpts with multiple policy sub-labels.
- Performance in Classification: results from classification with simple methods and Bert will be shown
Text Visualizations
This file will display visualizations of the text based on the labelled categories, shown as the circles on the distance plot. This plot also shows the word distributions associated with each category. The word distributions on the right show the most common words in each category when lambda=1, and the most specific words to the category when lambda = 0, computed by the relevance metric.
The categories are labelled on the plot as numbers, and the corresponding label titles are:
Topic 1: Guns, number of words: 126276, number of excerpts: 745
Topic 2: OtherAdv, number of words: 70893, number of excerpts: 425
Topic 3: MentalHealth, number of words: 42994, number of excerpts: 233
Topic 4: Other, number of words: 18683, number of excerpts: 108
Topic 5: Practice, number of words: 11622, number of excerpts: 67
Topic 6: InfoSharing, number of words: 9390, number of excerpts: 51
Topic 7: VictimAdv, number of words: 8617, number of excerpts: 51
Topic 8: Immigration, number of words: 1817, number of excerpts: 12
The size of the circles correspond to the size of that category. Also, if hovering over a word in the chart on the right, the size of the circles will adjust proportional to count of that word in each category. Clicking on a topic will display that topic word distribution, and clicking away on the empty part of the distance plot will show the overall word distribution of all the documents.
Label Counts and Multi-Label Co-Occurrence Counts
Label counts
First we can examine directly the total counts of each sub-label in the both the testing set. These plots simply re-iterate what was shown by the size of the bubbles in teh previous plot.
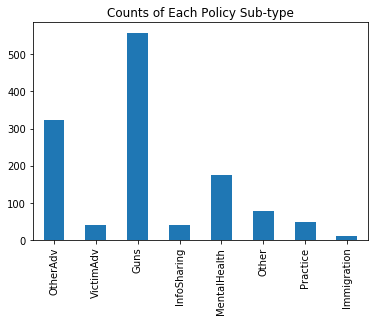
It is clear guns and otherAdv labels are the most common.
Label and Co-Occurrence Counts
This section will give more details on the counts of each label in the test and training set.
This can give insights about which labels are most common, and also which labels occur most commonly together. There are seven sub-labels of accountability, so theoretically, it if each label was independant, there would be a possible 2^7 combinations of labels present in the data.
Most likely, certain labels are most likely to co-occur. By co-occur, I mean the same excerpt has been given two labels. For example, if one exerpt was labelled with both mental health and guns, then those two labels have one co-occurence counts.
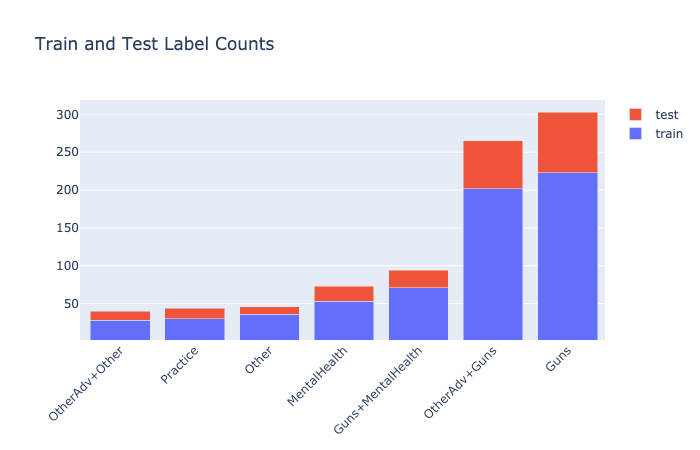
Computing the co-occurences is displayed in the following plot. The first thing to note, is that there are no excerpts with more than three labels co-occuring. They predominantly have either one or two labels per excerpt. There is a significant number of excerpts with two labels. This indicates that the dataset predominantly has the labels guns and mental health, and the co-occurences of “OtherAdv+Guns”, and “MentalHealth+Guns”. These two co-occurences of labels have more excerpts than most of the labels indiviually or any of the other co-occurence counts.
Note: it is possible to drag a rectangle around an area of interest on the plot to zoom into it. For example, a zoomed in view of the most common label and label co-occurrence counts is:
Classification results
Two classifiers were tested and trained with the sub-type labels. Bert, as explained in previous posts, is state of the art in nlp. It should drastically out-perform the logistic regression baseline in situations where the given labels are capturing meaningful content that goes beyond word counts. The reasons for comparable performance between Bert and logistic regression are:
- noise in the giving labels results in upper bound of inter-annotator agreement (typically ranging from 0.6-0.8 for this dataset)
- topics are distinctly identifiable by simple word counts methods, and do not require the encoded meaning present in the pre-trained bert network
- Bert is not using optimal parameters, and more testing should be done to improve its performance. Updated methods building on Bert, such as Roberta, could be used.
The implementations of the codes used to produce these results are: Bert, logistic regression.
Fscores
| Label | Bert | Logistic Regression | Number Excerpts |
|---|---|---|---|
| Guns | 0.96 | 0.96 | 742 |
| OtherAdv | 0 | 0.67 | 425 |
| Mental Health | 0.78 | 0.77 | 233 |
| Other | 0.67 | 0.68 | 108 |
| Practice | 0.25 | 0.59 | 67 |
| Info Sharing | 0.9 | 0.84 | 51 |
| VictimAdv | 0 | 0.29 | 51 |
| Immigration | 0 | 0 | 12 |
Precision/Recall
| Label | Bert | Logistic Regression | Number Excerpts | | ———— | ——:| ——————-:| —————:| | Guns | 0.97/0.95 | 0.96/0.96 | 742 | | OtherAdv | 0/0 | 0.64/0.70 | 425 | | Mental Health | 0.79/0.76 | 0.87/0.69 | 233 | | Other | 1/0.5 | 0.73/0.63 | 108 | | Practice | 0.75/0.15 | 0.71/0.5 | 67 | | Info Sharing | 0.9/0.9 | 0.89/0.8 | 51 | | VictimAdv | 0/0 | 0.67/0.18 | 51 | | Immigration | 0/0 | 0/0 | 12 |
Discussion
These results show that guns is abnormally high in performance for both bert and logistic regression. This topic has the most number of examples, so its performance should be higher than the others, but it is quite unexpected to be this high. The most likely explanation, is that there may be repeated data in the test and train set, and so further investigation of the data will be required to confirm this. An alternative explanation could be that all the excerpts with the topic “gun” contains the word gun, and all the excerpts in this dataset that do not have the word gun were also not given that label.
The next best performing topic was Info sharing with the logistic regression classifier. This is likely due to luck, because considering there were only 51 labelled documents with that topic, the test set would’ve had less than 10 examples. This is not a large enough sample size to consider this score as a conclusive result. However, it can tell us that this topic likely has some very strongly related terms that allowed the classifier to perform well in this data set. If these terms generalize well to unseen data, then this topic could be worthwhile to pursue for future research.
Next, mental health performed quite well with both bert and logistic regression. The size of data is large enough to give more insight that this classifer may be able to generalize well on unseen data.
Finally, another big surprise is that the second biggest category “otherAdv” performed very badly with BERT, but very well with logistic regression. The issue with the bert classifier could be that the training data given happened to be very niche, and so the classifier did not generalize to perform on the test set (over-fitting). More investigation and experimentation with Bert model parameters would be required to address this issue.
Suggestions for Next Steps
Based on this analysis, next steps I would take would be to focus on the sub-type categories that have the most labels, as well as the co-occurence sub type labels, and create a new set of labels: Guns, Mental Health, Guns+OtherAdv, Guns+MentalHealth, and Other. This would result in 5 reasonably similar size sub-topics of Policy. Then, I would proceed with a multi-class classification testing (as opposed to testing one at a time in binary classification as I have done in this experiment).
The Guns topic is the most reliable and for future studies, this classifier could likely be used to identify excerpts discussing the topic of policy-guns.
Note, I did try multi-label classification with bert as well, but the results turned out to be strange, with each sub-topic getting almost exactly 0.5 in f-score. I would proceed with the pytorch bert implementation (instead of this code) for future testing.